C# MD5 hashing in 2024

Inhaltsverzeichnis
C# MD5 hashing nowadays
Being in the need of creating a C# MD5 hash for one of my projects has been a while now. Due to one of my recent customer projects I got back to it and I noticed, that I don’t have a matching blog post. Well, so I just decided to create today’s blog post – enjoy 😀. As I don’t creating „half things“ I will also go through some basics and FYI: We won’t use any kind of external library here.
Back to the basics – „data“?
When trying to understand hashes we have to first go back some steps to the basic knowledge of storing data in general. Right away, we could begin with something like a simple string as „computer“. For sure there could be other data types, but a string or even a simple number is the perfect fight for the start, I think.
How data is stored?
Everyone’s talking about those things called „big data“, „data analyst“ and whatsoever, but what actually is data? How is it being represented inside a modern day computer? In terms of a modern computer, data is actually stored as so called „bytes“. A single „byte“ is actually the the smallest addressable unit of memory inside a computers context.
A byte actually consists of different single so called „bits“, in total 8 of them. The are „connected“ and you can imagine it like in the following illustration:

So in the image you can see, that there are 8 single bits acting together as one byte. Each single bit can be in one of two states: It can either be 1 (on), or otherwise it’s 0 (off). Any bits state change, will also change the overall value which is being represented by the byte.
Some data examples
At this point, I will try to provide some basic examples to help forming the basic knowledge. Please keep in mind, that I can’t go into this topic too deep. Of course you can go ahead and skip this part, if you are already thinking: „Nah, that’s only for babies, I already know everything there“.
The first data example – the number 42
In our first data example, we will take a look at the simple and basic number 42. Let’s see, how the data structure called byte – and therefore the bits – will represent this number.

If you take a look at this binary / bitwise example from above, you can see, that there’s a mix of zeros and ones. Don’t think, that those bits are some kind of random, they follow a specific order and specific „values“ being on or off. In the case of our number 42, the binary representation would be „00101010“.
A basic & quick explanation
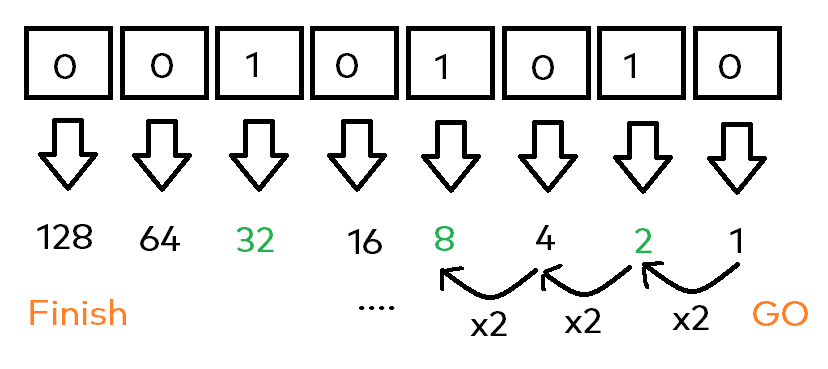
I will try to explain this basically like so: Each bit represents a single (and own) value itself, for example the outer right one being a 1. The next one – again, from the right side – is a 2 and then the chain continues. You could say: Start from right, being a 1 and double the value for each bit till you are on the left end.
We will talk more about this in just a few seconds, let’s now just focus on the „is on“, or „is off“ at first. So when calculating the final value of that byte, you only take those „bit values“ into account being on. In our example, this would sound like this:
- The bit on the outer right, being bit with value 1 is off, so just ignore it
- Going to the second bit from the right, it’s on -> take it’s value being 2
- Next, the bit with value 4, is off, ignore again
- And finally, the bit with value 32 is on -> again, take it!
Finally, we are having the following values (taking the „active“ ones): 2, 8 and the 32. If you sum this up, you will have our desired number called 42 🎉! Here’s another image making it – hopefully – even clearer:
How about a string – „MyPassword123“
So after exploring the easy „one simple number only“ example, we will now continue with a more complex string. Even though strings being more difficult on the first glimpse, they follow analog rules when being „stored“.
Right now, there would be the right place to start talking about something called character encodings. For now I will take a bit of a shortcut not going into those to deep, at this moment you should only take not of one thing: We are going to use the ASCI table. Next, let’s try to use the table for decoding our displayed number into a string representation.
Looking at the ASCII table and more specific at for example the letter „M“, you can see, that it has the code „077“. Just for fun right now, use your keyboard and hold down the „alt“ key. Type the just found code and release your „alt“ key again. Now you should notice an appearing „M“ letter 😎 – nice!
Looking at the M’s bitwise equivalent
Now we are going to look at how the letter „M“ is actually stored in its binary form. For this, we will check, how the number 77 would be displayed as binary number string.
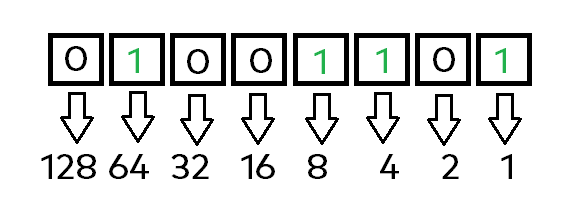
Using the little rulebook / algorithm learned from above, we will repeat it for this number / binary representation. Again, start from the right side having the value 1 for the first bit, then double it 7 times going to the left. In the end, check which bits are actually active and sum their values:
- Bit 1 -> on = 1
- Bit 3 -> on = 4
- Bit 4 -> on = 8
- Bit 7 -> on = 64
After listing those up, just sum those numbers and voila, we have our number „77“. Now I will actually save you from watching me repeat this process for each letter inside our string. Here is the complete string being represented as binary format:
01001101 01111001 01010000 01100001 01110011 01110011 01110111 01101111 01110010 01100100 00110001 00110010 00110011What actually is a hash?

After we now know (or knew before), how data is stored inside the computers memory, we will now go further. I think the most basic and easy explanation for a hash is as follows: „Take some value, put it into the hashing algorithm, get an output“. One important point is, that the same values being input, will result in the same output values.
Take at look at the following example hashes, before we continue:
- 0cc175b9c0f1b6a831c399e269772661
- 973d98ac221d7e433fd7c417aa41027a
- 7618ca3b69910d35e18dd998d4b2830b
Now I will show you same basic and important rules about hashing in general.
The source is unknown
The values from above seem to be a whole mess of nonsense, right? Actually, they aren’t, honestly you know at least two of those three values. This brings us to the second important point about hashes: You don’t know the origin / the source. A bit later, we will see, why this will be very important in some contexts.
The output length is fixed
Even though the first hash from above is only a small letter called „a“, it still seems pretty big. Looking at the second one – which was our password – it became a bit longer as well. The real interesting one is the last hash, where we actually computed a hash for a whole image file.
An MD5 is always 128 bits and therefore 32 hex digits long (means using the hexadecimal notation). The hex notation only needs 4 bits for each character, where you can easily calculate yourself: 128 / 4 = 32. Knowing this, you can store MD5 hashes in your database as char(64) field.
It only goes in one direction
The last important thing to note is, that hashes are irreversible, so you can hash, but can’t go back to source. Later, we will see why this could actually be a nice advantage instead of a problem. So now it’s time to step into the next sub-topic being „the why“.
Why computing hashes?

After digging into the basic things, you could now ask yourself: „Why should I sometimes compute hashes in the first place?“. Theres one important example where get in touch with it almost everytime.
Registration, signing in, etc.
When thinking about hashing, my mind basically automatically switches to the topic of application logins. I think everyday we are going through plenty of authenticatino processes, where some hashing algorithm is in play (at least behind the scenes).
Imagine visiting your well known app login screen, you enter your credentials just as usual like the username „robert“ and the password from above „MyPassword123“. When pressing the login button, it will mostly send a request to the server backend system. The code running on the server side will then try to find a corresponding user for the provided username. If no user could be found, then we will just get a typical matching error.
Time for hashes
After the steps above, the interesting part with hashes will happen next, so after an actual matching user could be found in the database. The system now hashes the provided (sent) password with the configured hashing algorithm. Then it will compare the just computed hash with the hash being fetched from the database – which is obviously stored there.
Now, go a step back and think about my argument saying: „Hashes can’t be reversed“, this is the time where this comes into play. Through the last years you will probably have heard about those typical news headlines like „200.000 user datasets have been stolen from blabla database leak“.
Taking the data protection considered things apart, there’s one more point being horrific here: „What the F – who has my password now 😭?“. Well, if done right – means with a proper hashing algorithm – nobody will have your password. Nobody will therefore be able to easily login with your leaked email and password in for example PayPal.
Conclusion
In my opinion, the core concept of using hashes is providing additional value in security based contexts. The three core attributes of a hash are basically: „It works in one way only“, „The output length is fixed“ and „the source is unknown“. This beautifully adds more security when storing userdata inside your database like a password or something a pin code, because if someone steals it, they won’t be able to use it.
Does that mean hashing is encryption? Be careful when using MD5 nowadays!

Oh lord, this is one of the basic misconceptions when talking with some unexperienced developers for sure. Many people still think, that hashing actually means encrypting something. Especially as a freelance developer and therefore seeing so many different developers and companies, I made some experiences in this direction. To quickly say it beforehand: Hashing is not encrypting & decrypting.
When taking a look at one basic argument you will quickly find out why, again, remember my argument: „Hashing only goes in one direction“. But if you now think about encryption, there is some input being encrypted and there is a possibility to legimately decode it back.
A dangerous problem especially with MD5 – collisions
If you have spend quite some years in the world of programming, you may already have heard of it: MD5 isn’t considered cryptographically secure anymore. Honestly I don’t know how long out of my head at the moment, but it has already been some years. Just a few days ago, I saw one of my tunesian customers actually still using the Message Digest Algorithm 5 (through freelancers work).
I personally think, that you can actually use MD5 in some cases, but please (for god’s sake), please avoid it considering security based contexts. Another problem next to collisions is MD5 being to fast which enables too easy guessing.
Adding more security using salts

Being around in the world of programming you might have already heard of a thing called a „salt“. If so, this would actually pretty good, because it’s one additional gotcha considering security aspects. Think about your hash being a nice food being cooked. Adding a yummy bit of salt you could actually improve the taste of your food (being the hash algorithm).
After hearing that metaphor from above, you can basically say that hashes are „something being added“ to the source input being hashed. One nice aspect is, that if two users choose the same password, you won’t be able to see it. Otherwise you could kinda guess by „Oh, those users have the same hash“.
Even though I pretty much love rainbows, there is one additional thing, where salted hashes can help against as well. I’m talking about the common hacking method called / using „rainbow tables“. A rainbow table is a premade table of hashed values, where you can try matching records. The future me will eventually go a bit deeper into that, for now that’s enough to know here.
Got the salt – and now?
When first learning about salts, I can guarantee you, that you are totally not alone with that question. If you have successfully generated your random salt, you will ask yourself: „Nice, but how am I supposed to let it come into play on the next login attempt?“. Let me tell you, that you can just store the salt alongside in the database, this way you can use it on login check.
What about file hashes?

Me – at the time of writing this post being 30 – I still enjoy playing games, on PC and as well and consoles. If you have a similar bias, then you will most likey came across some site advertising downloads of games, etc. Sometimes there is a hash being displayed on this download page – for the corresponding download.
When downloading files, there are some things that can go wrong or even revealing themselves as a security problem. Sure there can be less and more problematic things, but think of getting not the actual game client / rom you wanted? You basically enter your login details which then could be send to the malicious producer of this software – while you are still thinking: „Yes, I got the right game“.
Don’t trust, validate!
This basic rule went deep into many persons brains, when the bitcoin slowly settled into peoples memory. It is actually a great saying, which essentially explains, what these file hashes are all about. With those, I – as a manufacturer / developer can tell you the follwing. „This is the original and correct state of the software I’m providing to you“.
After downloading my software or game, you could create a hash to check the file yourself. This would make sure, that you actually got the right one. This ensures that no corruption has happended during the download due to like an instable connection. But most importantly this means: No sneaky hacker has given you a little trojan which he could use to spy on your actitivies and credentials with. This is especially essential when downloading your software through some sort of sharing network.
Modifying your favourite game
Another example could be like one of your favourite nostalgic games put into a ROM. Some developer might brought the game back to life by making a nice mod for it. To actually install that ROM, the developers patching program mostly needs the same starting point. Therefore a hash could express: „This is the exact version my patcher needs“.
Quick examples – C# MD5 hashing
So, if you have no time for more blabla, then just take a look at those quick examples on „how to create an MD5 hash in C#“. Finally I can stop talking and start coding for you, haha 🤓!
The older but still OK-working way
In the first step, we create an instance by the MD5 classes create factory method. Then we are getting the bytes of the actual text by calling GetBytes on our desired encoding. After that, we are computing the actual hash bytes and store them into the corresponding variable. Then, we create a basic StringBuilder to save up on resources building the final string. In the last step, we are adding the hex representation of each byte to the stringbuilder with the format being „x2“. This version should work somewhere up to .NET 4.8, something like that.
public static string MD5(string clearText)
{
using var md5 = System.Security.Cryptography.MD5.Create();
var bytes = System.Text.Encoding.UTF8.GetBytes(clearText);
var hash = md5.ComputeHash(bytes);
var sb = new System.Text.StringBuilder();
foreach (var byt in hash)
sb.Append(byt.ToString("x2"));
return sb.ToString();
}
The newer version
In this version we can actually use the factory method of the HashAlgorithm base class, dynamically creating our hash algorithm instance. Then we can also avoid using a stringbuilder, because the Convert class just has a method we can use now. Keep in mind that I’m expecting „algo“ not to be null, therefore the „!“.
public static string MD5(string clearText)
{
var sb = new StringBuilder();
var bytes = Encoding.UTF8.GetBytes(clearText);
using var algo = HashAlgorithm.Create(nameof(MD5));
var hash = algo!.ComputeHash(bytes);
return Convert.ToHexString(hash);
}
Hashing a whole file – the last example
In this last example I will show you, how you can create a C# MD5 hash from an actual file. Watch out, in this example I’m not using the „nameof“ expression, cause the name of the function changed.
public static string MD5FileHash(string filePath)
{
var algo = HashAlgorithm.Create("MD5");
using var filestream = new FileStream(filePath, FileMode.Open);
// should be zero by default anyways..
// filestream.Position = 0;
var hashValue = algo.ComputeHash(filestream);
var hash = BitConverter.ToString(hashValue).Replace("-", "");
return hash;
}